Cómo trabajan los content curators
En esta serie de posts hablamos con profesionales sobre cómo aplican la content curation a sus proyectos y productos
Jesús Hernández: “La red me ha aportado muchas cosas que trato de devolver en la medida en que soy capaz “

Jesús Hernández es maestro en el primer ciclo de ESO, Vicedirector en el IES María Pérez Trujillo, coordinador de HangoutEDU, miembro del equipo coordinador de la Red Social de Cine y Educación Cero en conducta y miembro de EducAppsAventura. En Twitter, @jhergony.
Sigo a Jesús desde hace tiempo con admiración por su enorme y generoso trabajo de curación y difusión de contenidos en el sector de la educación. Su trabajo en List.ly, blog y Twitter bajo la marca «Crea y aprende con Laura» es ya todo un referente para muchos content curators profesores de este país. Aquí nos cuenta algo del día a día de su trabajo como curador de contenido.
¿Puedes presentar brevemente los productos que realizas basados en curación de contenidos ?
La principal labor de curación de contenidos la llevo a cabo a través de mi blog, Crea y aprende con Laura, un blog que comencé en 2007. En el blog busco todo tipo de aplicaciones webs y móviles útiles para educación, materiales educativos, experiencias educativas que considero interesantes, cortometrajes, actividades que desarrollo y reflexiones educativas. Publico casi diariamente.
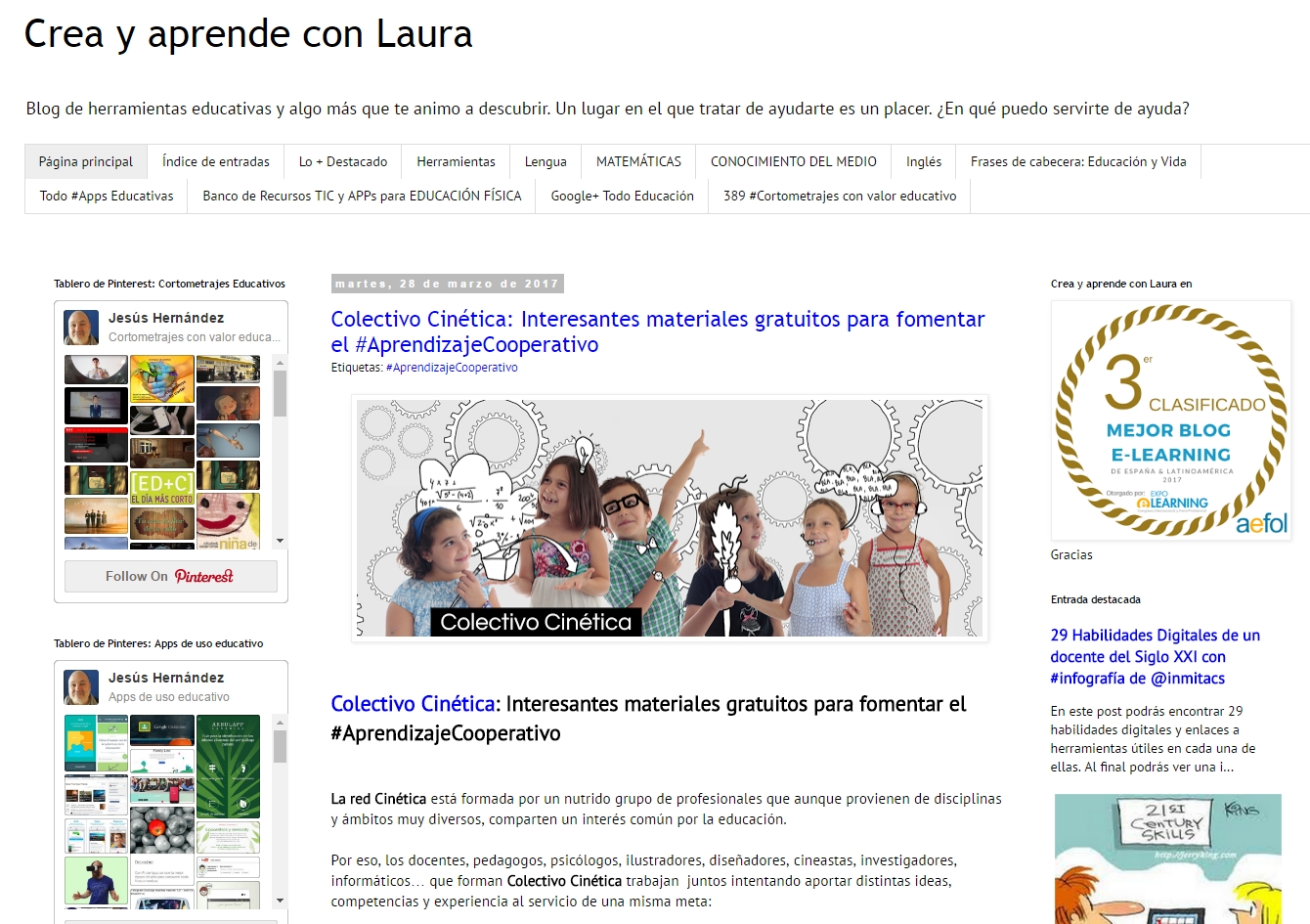
También tengo una lista de cortometrajes con valor educativo en List.ly que se encuentra en su Trending Lists. Esta lista nació en otro blog específico de cortometrajes que tenía, pero que integré en mi blog principal y en List.ly.
También desarrollo mi labor en Twitter, donde mi nick es @jhergony. Aunque participo en más redes, es realmente en esta en la que realizo más curación de contenidos.

List.ly Cortometrajes con valor educativo
¿Cómo fueron tus inicios en la curación de contenidos?
Siempre me gustó perseguir materiales y estar al día de novedades, curiosear y surfear detrás de cualquier noticia que me atrajera y compartirlas con los compañeros. Cuando comencé con los blogs e internet empezó a hacerse más general, comencé a buscar materiales y a compartirlos, pero realmente aportaba poco más allá de su recopilación.
Después, comencé con Crea y aprende con Laura que en realidad no era mi blog, sino uno que hacía junto a mi hija y para ella. Colocaba materiales para ella. Posteriormente, las profesoras de su colegio comenzaron a visitar el blog y a solicitarme que les buscara materiales para actividades concretas. Ese se puede decir que fue en momento en el que el blog se destinó de una manera más consciente a la búsqueda de materiales, sobre todo, cuando Laura me dijo que se había construido dos blogs y que me quedara yo con ese. Como en este tenía ya por aquel entonces bastantes más visitas que en cualquiera de los que realizaba, decidí hacerlo totalmente mío. Esa fue la última fase de este blog, que ya dejó de estar tan enfocado a primaria y se centró más en mis intereses.
¿Qué objetivo persigues con la realización de estos productos?
Lo primero, satisfacer mi curiosidad y aprender cosas nuevas. Es algo que va en mí. Lo segundo, poder servir de ayuda a compañeros. Es algo que también llevo en mi adn, con blogs, sin blogs, con internet y sin internet. También he ido aprendiendo de la Red y de las personas que habitan el ella. Creo firmemente en que todo lo que uno recibe debe devolverlo a la sociedad y creo que la Red me ha aportado muchas cosas que trato de devolver en la medida en la que soy capaz.
¿Cuál es tu sistema de trabajo en las fases de búsqueda y de selección de contenidos? ¿En qué herramientas te apoyas principalmente y cuál es el tiempo estimado de dedicación?
Las fases de mi trabajo suelen comenzar por la fase de “radar” alerta ante cualquier estímulo que me sugiera algo. Siempre miro al lado cuando busco algo. En muchas ocasiones descubro cosas mientras busco otras, porque me gusta mirar lo que aparece al lado. Sin ir más lejos, mientras escribía las respuestas a estas preguntas a través de un Documento de Google, veo que me aparece en la parte inferior derecha una pequeña pestaña, Exploración, que llama mi atención. Hago clic en ella y veo que ha realizado una búsqueda en Google Drive y de imágenes sobre los temas que estaba escribiendo.
Utilizo bastantes herramientas, aunque me centro en unas pocas de forma sistemática. Desde las más clásicas (un periódico, la radio, la tele) en las que un radar me avisa de que debo profundizar e informarme sobre algún tema, a las más específicas. Fundamentalmente utilizo:
- Feedly combinado con Pocket : con Feedly localizo y filtro fuentes y con Pocket las clasifico y les doy un último filtrado;
- Twitter, verdadera plataforma de curación de contenidos si sabemos sacarle partido al utilizar sus propias herramientas o combinándolas con otras como Tweetdeck, muy recomendable;
- Alertas de Google, muy práctica;
- Pinterest, una red muy rica que permite encontrar de un vistazo cantidad de contenidos interesantes y poder profundizar en ellos;
- Scoop.it, la uso solo en la fase de búsqueda y filtrado, siguiendo muchas cuentas;
- sigo algunos Paper.li seleccionados;
- y desde hace un tiempo, me encanta Nuzzel.
- Por último, cuando tengo enfocado un artículo, profundizo acudiendo a las herramientas de búsqueda de Google para terminar de perfilarlo.
Y finalmente, publico y comparto.
Le dedico aproximadamente unos dos horas diarias, aunque se puede decir que siempre estoy alerta, incluido cualquier comentario de un alumno que me descubre una herramienta (esto me interesa por mantenerme cercano a sus intereses).

Feedly y Pocket, el binomio curador (ilustración de Jesús Hernández)
Una vez has seleccionado los contenidos que quieres curar y difundir, ¿cómo procedes a continuación? ¿Utilizas alguna técnica o sistema determinado para aportar valor a esos contenidos?
Suelo destacar los elementos que desde mi punto de vista hacen útil ese contenido para educación, realizo comentarios personales, sugiero ideas para su utilización, trato de esquematizarlos para hacer accesibles y más visibles los contenidos y sus partes destacadas.
Si tenemos en cuenta todas las fases, algunos posts me cuestan horas y días en algunos casos.
¿Qué tipo de difusión o redifusión posterior haces de esos productos en otras plataformas o servicios?
Utilizo para difundir mis publicaciones: Twitter (con hashtags específicos), Google +, Linkedin, Pinterest, Facebook, Scoop.it, correo, newsletter, RSS,…

Tuit de Crea y aprende con Laura
¿Qué tipo de interacción mantienes con la comunidad que sigue tu trabajo?
Procuro tener bastante contacto con las personas que me siguen, tanto analizando los contenidos que les interesan como tratando de responder a sus preguntas, bien a través de posts o bien particularmente. Muchos de los posts que escribo han sido sugeridos por preguntas de compañeros. Cuando conozco la respuesta, directamente la escribo y cuando la desconozco, me sirve para investigarla y aprender.
¿Haces algún tipo de seguimiento o medición de tu curación, y con qué herramientas y frecuencia?
-Las primeras herramientas que utilizo son las que ofrece mi propio blog: número de visitas en el momento (interesante para saber si el post va a tener resultado o para saber si es una buena hora de publicación) por día, semana, mes, en cualquier momento, por entradas, fuentes de tráfico y público.
-Después, utilizo Google Analytics, con sus informes integrados (informes de audiencia, adquisición, comportamiento y conversión). Creo segmentos y hago comparativas.
-También utilizo Alexa, Analytics de Twitter, herramientas para medir hashtags como Hashtagify.
La frecuencia de consultas:
- en el blog diaria,
- en Google y Twitter Analytics regularmente,
- en Alexa de vez en cuando,
- y en los hashtags cuando me interesa hacer un seguimiento de alguno en concreto.
¿Cuáles consideras que son los puntos fuertes y débiles de tu trabajo? ¿Cómo crees que puede evolucionar en el futuro?
Como punto fuerte, la diversidad de fuentes construidas a lo largo de los años. Como debilidad, la falta de tiempo para lo que me gustaría hacer. Mi evolución está vinculada con el deseo de seguir aprendiendo.
Desde tu perspectiva ¿Cuál es tu punto de vista sobre la curación de contenidos en la actualidad y en el futuro inmediato, tanto a nivel global como en concreto en su aplicación en el ámbito de la educación?
Quiero pensar de manera optimista, porque creo que por muchas máquinas que nos puedan ayudar y facilitar el trabajo, el factor humano debe de estar presente. Aunque el Big Data, el Machine Learning y la revolución robótica que está a la vuelta de la esquina, con el aumento de sistemas de control y seguimiento, me hacen ser algo pesimista.
A pesar de ello, trato de confiar siempre en el ser humano que es capaz de lo mejor y lo peor. De hecho, la falta de curadores humanos parece estar haciendo que se propaguen las falsas noticias.
¿Hay algún ejemplo de content curator que quieras destacar y /o algún ejemplo de producto realizado con curación de contenidos que te guste especialmente?
Bueno, destacaría al que considero mi maestro en estas lides y del que he aprendido y sigo aprendiendo mucho, Javier Guallar y su web, Los Content Curators. También, Robin Good y su Content Curation Official Guide.
¡Muchas gracias, Jesús!
About Javier Guallar
 Profesor de Documentación y Comunicación, Editor, y Content Curator.
En UB, revista Profesional de la información (EPI), libros Profesional de la información y EPI Scholar (Ed.UOC), Los content curators. Coautor libros "El content curator", "Las 4S's de la content curation", "Calidad en sitios web", "Prensa digital y bibliotecas".
Mi newsletter: https://www.getrevue.co/profile/jguallar
Profesor de Documentación y Comunicación, Editor, y Content Curator.
En UB, revista Profesional de la información (EPI), libros Profesional de la información y EPI Scholar (Ed.UOC), Los content curators. Coautor libros "El content curator", "Las 4S's de la content curation", "Calidad en sitios web", "Prensa digital y bibliotecas".
Mi newsletter: https://www.getrevue.co/profile/jguallar



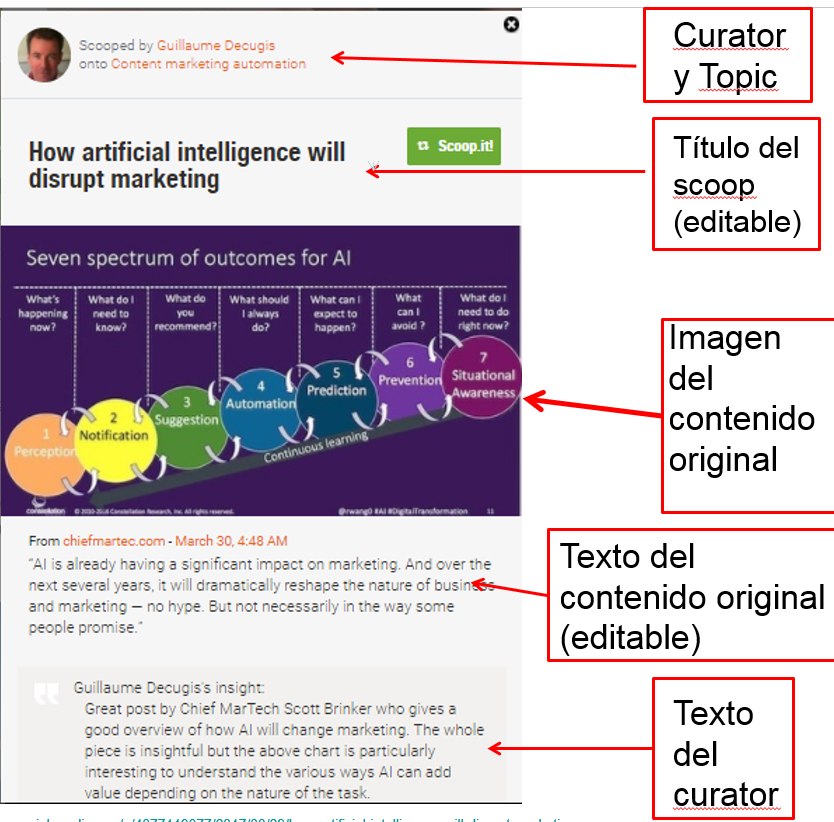
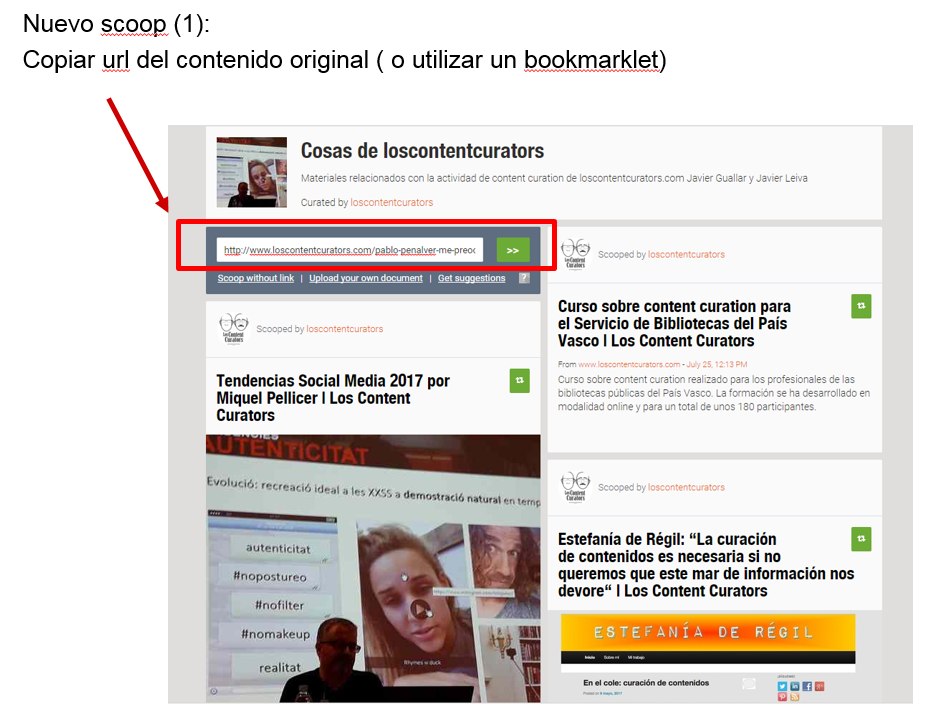
 1. Topic de destino de la publicación. En el caso de que el curator tenga varios topics en su perfil se muestra un desplegable con los mismos, y debe asignar la publicación a uno de ellos.
1. Topic de destino de la publicación. En el caso de que el curator tenga varios topics en su perfil se muestra un desplegable con los mismos, y debe asignar la publicación a uno de ellos.


{kind=link}